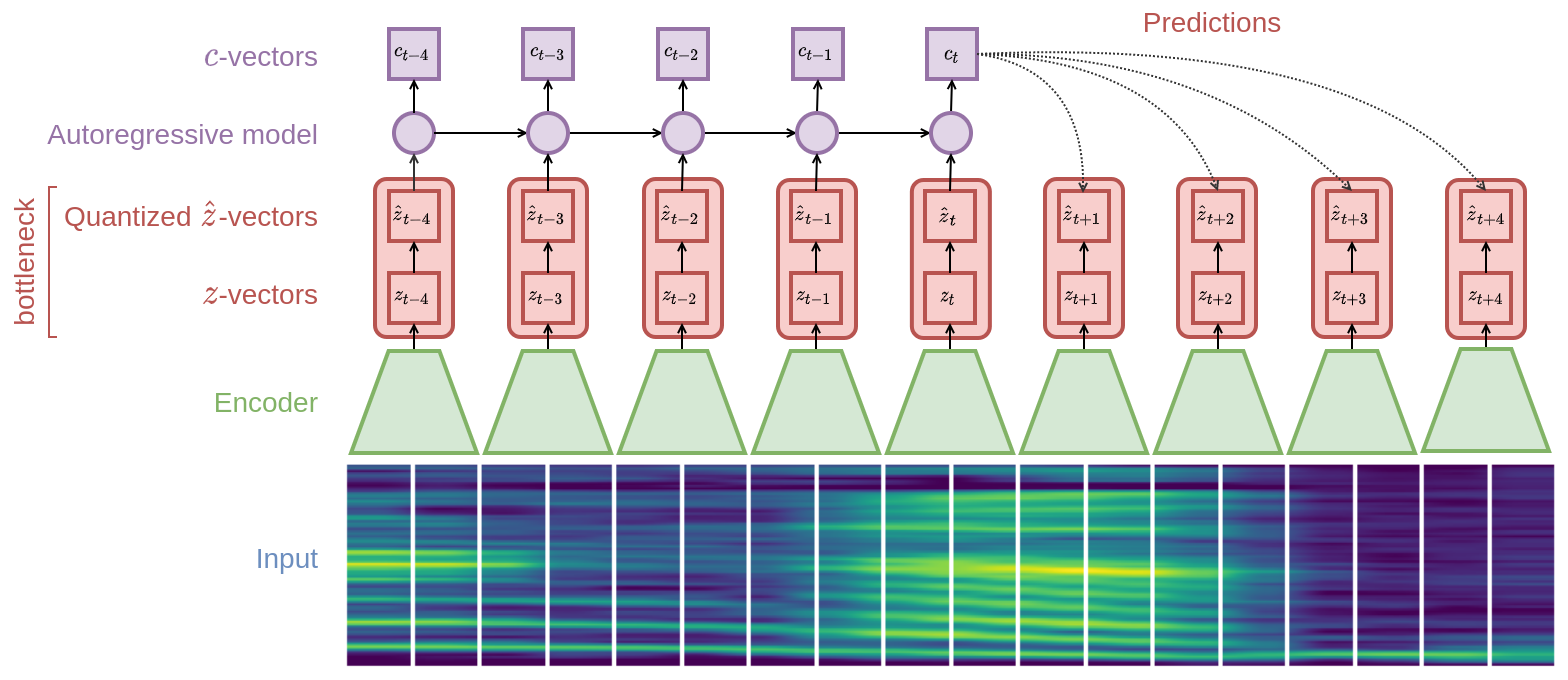
Fig 1: VQ-CPC model architecture.
All audio samples are generated using the scripts and pretrained weights at https://github.com/bshall/VectorQuantizedCPC.
For samples from the VQ-VAE model see https://bshall.github.io/ZeroSpeech/.
English samples
Speaker - V001
| V001 | other conversions | |||||
|---|---|---|---|---|---|---|
| source | converted | target | S040 | S056 | S074 | S090 |
Speaker - V002
| V002 | other conversions | |||||
|---|---|---|---|---|---|---|
| source | converted | target | S040 | S056 | S074 | S090 |
Indonesian samples
Speaker - V001
| V001 | other conversions | |||||
|---|---|---|---|---|---|---|
| source | converted | target | S028 | S110 | S112 | S154 |